
-
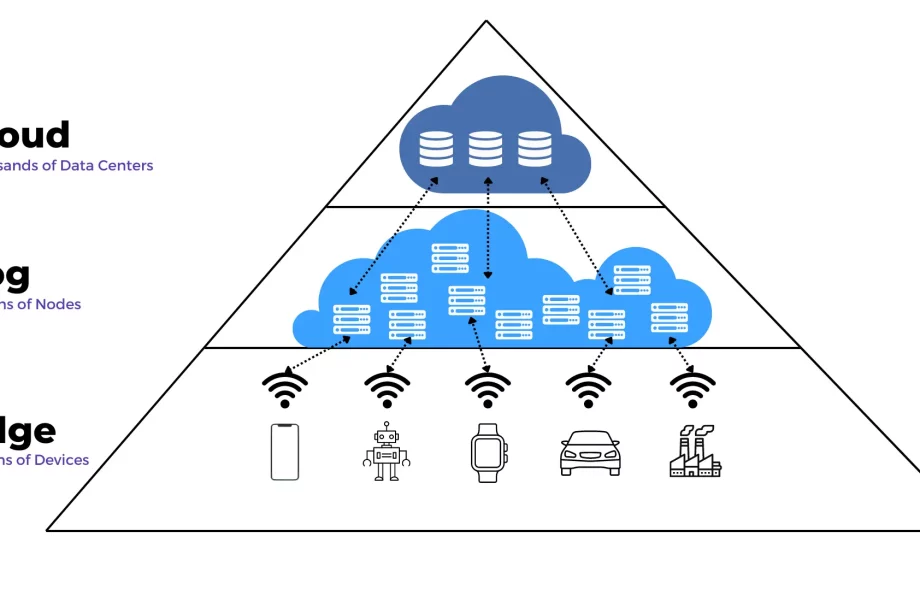
Extends cloud capabilities closer to the network edge but in a more regionalized or hierarchical structure.
-
Offers more processing power and storage than edge devices alone.
-
Ideal for large-scale, interconnected environments where coordination between multiple edge nodes is needed.
-
Supports orchestration, analytics, and security at a regional level.
Example:
In a smart city, fog nodes may aggregate traffic data from multiple intersections and analyze it to optimize city-wide flow without relying on cloud-only processing.
Key Differences Between Fog and Edge Computing
| Processing Location | On or near the device (e.g., sensors, gateways) | Between edge and cloud (fog nodes/servers) |
| Architecture | Device-level, decentralized | Hierarchical, with intermediate nodes |
| Latency | Lowest latency (microseconds to milliseconds) | Slightly higher but still near real-time |
| Data Handling | Processes and filters raw data at the source | Aggregates and processes regionally |
| Use Case Scale | Best for localized use cases | Better for distributed systems across regions |
| Cloud Dependency | Less reliant on cloud | Often complements both edge and cloud |
In essence, edge computing is about processing data at the outermost edge of the network, while fog computing adds a middle layer that balances load, coordinates devices, and extends cloud services closer to where data is generated.
When to Use Edge vs Fog Computing
Use Edge Computing When:
-
Ultra-low latency is critical (e.g., autonomous vehicles, medical devices).
-
Data processing must occur immediately and locally.
-
Devices can operate independently of broader networks.
-
You want to minimize cloud usage to reduce costs and privacy risks.
Use Fog Computing When:
-
You need to coordinate multiple edge nodes over a wide area.
-
Intermediate analytics or data aggregation is beneficial.
-
Scalability and integration with cloud services are essential.
-
Applications require regional processing but not necessarily right at the endpoint.
In practice, many organizations deploy both paradigms together, creating a layered architecture that leverages the strengths of each.
Real-World Applications
Smart Cities
-
Edge: Cameras and sensors detect traffic violations or congestion.
-
Fog: Regional fog nodes analyze data across city zones and make decisions like rerouting traffic or adjusting signals.
Healthcare
-
Edge: Wearables and diagnostic tools analyze patient vitals in real time.
-
Fog: Fog nodes aggregate patient data from multiple sources for hospital-level analytics and reporting.
Industrial IoT (IIoT)
-
Edge: Machines detect anomalies on the shop floor.
-
Fog: Local servers handle batch analytics, machine learning models, and predictive maintenance across departments.
Advantages of Combining Both
By integrating edge and fog computing, organizations can build scalable, resilient, and intelligent networks capable of:
-
Performing real-time analytics at the device level.
-
Managing data overflow through regional fog nodes.
-
Reducing data center load and operational costs.
-
Enhancing cybersecurity through layered access and localized controls.
This hybrid model is particularly effective in next-generation deployments of 5G, AI inference, and multi-access edge computing (MEC).
Challenges to Consider
While edge and fog computing offer substantial benefits, they also introduce new complexities:
-
Device Management: Coordinating updates, security, and configurations across many distributed nodes.
-
Security Risks: Each device or node is a potential attack vector.
-
Standardization: Lack of universal protocols or platforms can hinder interoperability.
-
Latency Trade-offs: While both reduce latency compared to the cloud, architectural choices still affect performance.
Solutions include adopting containerization technologies like Kubernetes at the edge/fog level, employing zero-trust security frameworks, and embracing open-source edge orchestration platforms (e.g., EdgeX Foundry, OpenFog).
Conclusion
While fog computing and edge computing share the common goal of bringing data processing closer to the source, they differ in architecture, scope, and use cases. Edge focuses on ultra-local real-time processing, while fog introduces intermediary layers that enable broader coordination and analytics before data reaches the cloud.
Understanding these distinctions allows organizations to design optimal distributed systems tailored to specific performance, scalability, and cost requirements. As technology evolves and data continues to surge, both fog and edge computing will play essential roles in enabling responsive, intelligent, and efficient digital ecosystems.
glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp glasp
 :
https://nouvoericsfiks.blogspot.com/
:
https://nouvoericsfiks.blogspot.com/